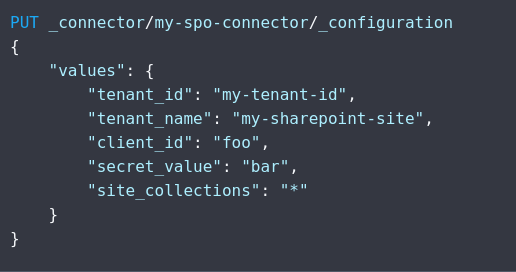
Opdaterer adgangskoden til en Connector til en database i Elastic via API. Mange organisationer har systemer som opsatere system konti og sætter nye koder på eksterne systemer. På den måde er det nemmere at sikere brugere og koder mod misbrug og samtidig ikke en byrde der skal huskes at gøres men kan ske automatisk.
Opsætning af Logstash pipeline som kopiere data til nye index
En typisk Logstash-pipeline består af tre hovedkomponenter: inputs, filters og outputs. Inputs er kilderne til logdata, hvor data indsamles fra. Filters er konfigureret til at forarbejde logdataene, f.eks. ved at ændre formatet, filtrere unødvendige data eller berige data med yderligere oplysninger. Outputs er destinationerne for logdataene, hvor de sendes til, f.eks. Elasticsearch, databaser, messaging-systemer eller andre steder.
Input i en Logstash-pipeline bruges til at indsamle logdata fra f.eks. Elasticsearch, Syslogs eller API kald, og sende dem til andre destinationsmuligheder (output) i Logstash-pipeline. Brug af Elasticsearch som input kan være nyttigt, når du ønsker at analysere eller forarbejde data, der allerede er indekseret i Elasticsearch, eller når man ønsker at overføre data fra Elasticsearch til andre datakilder eller destinationsmuligheder.
Nogle almindelige scenarier, hvor man bruger Elasticsearch input i en Logstash-pipeline, inkluderer:
- Dataforarbejdning: Logstash kan bruge Elasticsearch input til at indsamle data fra Elasticsearch-indekser, og derefter anvende forskellige filters for at udføre dataforarbejdning, såsom at ændre formatet, rense data eller berige data med yderligere oplysninger, før de sendes til en output-destination.
- Dataintegration: Logstash kan bruge Elasticsearch input til at integrere data fra forskellige kilder og sende dem til Elasticsearch til indeksering og søgning. Dette kan være nyttigt, når man ønsker at konsolidere og berige data fra forskellige kilder og samle dem i et index.
- Dataudveksling: Logstash kan bruge Elasticsearch input til at hente data fra Elasticsearch og sende dem til andre destinationsmuligheder, såsom databaser, messaging-systemer eller andre logningssystemer. Dette kan være nyttigt, når man ønsker at replikere data fra Elasticsearch til andre systemer eller bruge dataene i forskellige kontekster.
Det er vigtigt at bemærke, at Logstash er meget konfigurerbart, og der er mange andre inputs og outputs tilgængelige ud over Elasticsearch, afhængigt af de specifikke behov og krav til lognings- og dataforarbejdningsworkflowen. Elasticsearch input er blot en af mange muligheder, der kan bruges i Logstash-pipeline for at indsamle, forarbejde og sende logdata fra forskellige kilder til forskellige destinationer.
Opsætning af pipeline
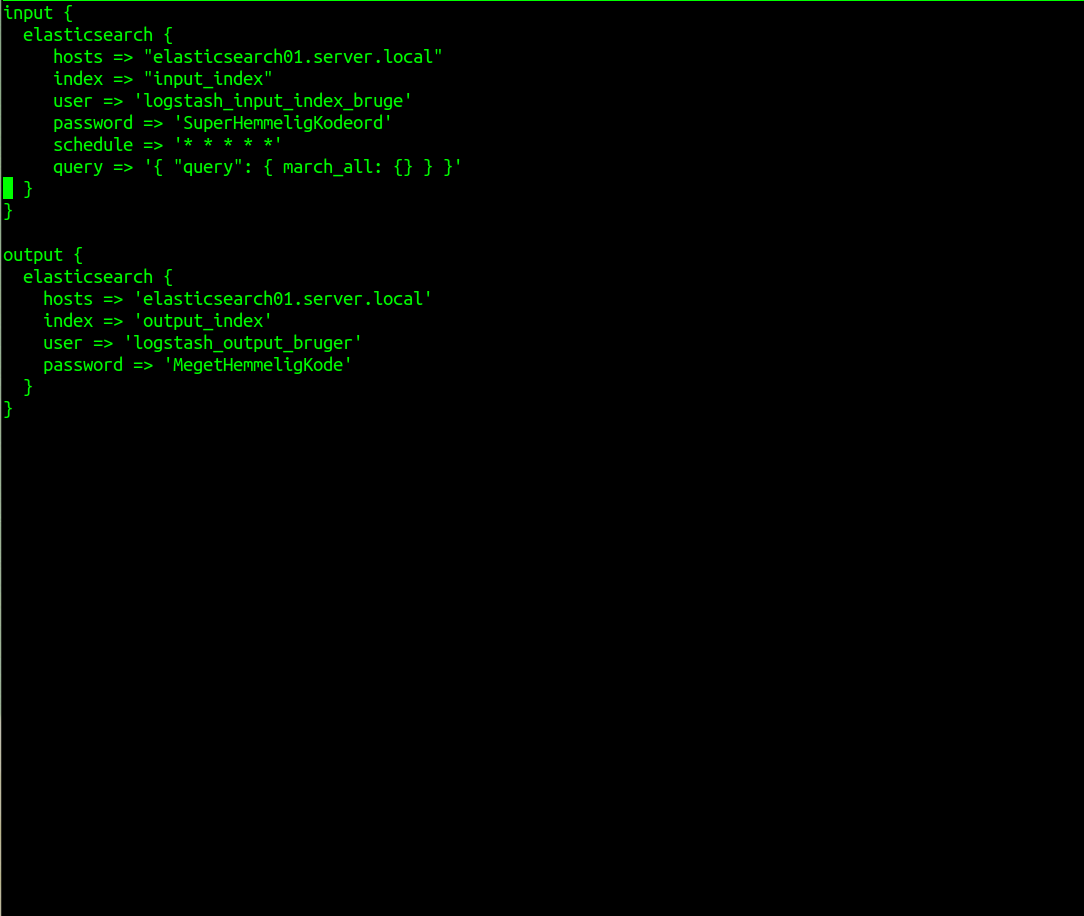
For at lave en pipeline i Logstash som henter data fra et Elasticsearch index kan man bruge følgende eksempel:
input {
elasticsearch {
hosts => "elasticsearch01.server.local"
index => "input_index"
user => 'logstash_input_index_bruge'
password => 'SuperHemmeligKodeord'
schedule => '* * * * *'
query => '{ "query": { march_all: {} } }'
}
}
I dette eksempel hentes data ud fra et Elasticsearch index her minut. Det defineres i ‘schedule‘ og med en ‘query‘ som udvælger alt. Du kan gøre ‘query‘ mere specifik hvis du kun vil have et del at dokumenterne ud af fra indexet.
Vær påmærksom på at der i dette eksempel ikke er med SSL.
Bruger og rettigheder
For at få adgang til data, kræves det tyopisk at du benytter en bruger og kodeord. Dette skal sættes op af en administrator i Elasticsearch.
Det anbefales altid at man har en specifik bruger til formåelt som kun har de rettigheder som der er brug for. Normalt vil mad derfor skulle bruge en bruger med ‘read‘ rettigheder til det index som du vil læse fra. Men for at scheduleretn også virker, skal du tildele ‘monotor’ rettigeden på cluster nuvau til denne bruger, ellers vil du får en 403 access denied fejl.
Relaterede indlæg