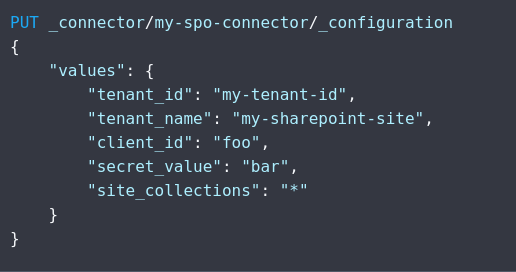
Opdaterer adgangskoden til en Connector til en database i Elastic via API. Mange organisationer har systemer som opsatere system konti og sætter nye koder på eksterne systemer. På den måde er det nemmere at sikere brugere og koder mod misbrug og samtidig ikke en byrde der skal huskes at gøres men kan ske automatisk.
Import at data fra SQL server til Elasticsearch
I Elasicsearch kan ben benytte en river til at importere data fra andre data sources. En river er en standard API som kan benyttes af plugins til at importere data. I Elasticsearch er der nogle standard rivers til f.eks. import af twitter, eller wikipidia. Men det er muligt selv at skrive sine egen river plugins som kan hente og ikke mindst opdatere data.
Jeg har fundet et river plugin, som hedder Elasticsearch JDBC river, den kan hente og opdatere data fra forskellige SQL servere.
For at installere pluginet skal du først stille dig i Elasticsearch home mapen. Hvis du har installeret Elasticsearch via deb pakken på en Linux server vil det være /usr/share/elasticsearcg/
cd /usr/share/elasticsearch
For at installere JDBC river pluginet skal du skrive følgende
./bin/plugin -install river-jdbc -url http://bit.ly/1dKqNJy
MySQL
For at kunne forbinde til en MySQL server skal du bruge en MySQL JAVA connector.
MySQL connector til JAVA kan downloades her
Pak den ud og lig jar filen ind i /usr/share/elasticsearch/river-jdbc/
MSSQL
For at kunne forbinde til en MSSQL server skal du bruge en MSSQL JAVA connector.
MSSQL connector til JAVA kan downloades fra Microsofts hjemmeside her
Pak den ud at lig jar filen ind i /usr/share/elasticsearch/river-jdbc/
Du kan godt installere begge eller flere connectore hvis du har brug for at kunne hente fra andre databaser.
Efter installation skal Elasticsearch genstartes. Husk at hvis du har flere noder skal JDBC river og de ønskede connectore være installeret på alle noder.
Når man opretter en river bliver den liggende der og det er så typen der bestemmer hvad der skal ske. Så den bliver altså gemt som alle andre dokumenter.
Med JDBC riveren kan man enten lave det som en “one shot” for at migrære data til Elasticsearch eller man kan sætte en scheduler, som så gør at den løbende køre og derved opdatere data fra SQL serveren i indexet i Elasticsearch.
Min erfaring med JDBC riveren er at den er lidt udokumenteret og at der er et par ting som ikke helt fremgår at der er en sammenhæng i. Jeg vil forsøge at gøre det lidt klarer her.
For at opsætte en river til en MSSQL server kunne det se sådan ud
curl -XPUT 'localhost:9200/_river/mit_mssql_data/_meta' -d '{
"type":"jdbc",
"jdbc": {
"driver":"com.microsoft.sqlserver.jdbc.SQLServerDriver",
"url":"jdbc:sqlserver://mssql-server:1433;databaseName=database",
"user":"sql-bruger",
"password":"sql-kode",
"schedule" : "0 */1 7-18 ? * *",
"sql": [
{
"statement" : "SELECT ID AS _id, name FROM tabel WHERE felt1 = ? AND felt2 = ?",
"parameter" : [ "noget", "andet" ],
"callable" : false
}
],
"poll" : "30s",
"index" : "mit_index",
"type" : "min_type"
}
}'
Det første man skal ligge mærke til er selve URL, her er der defineret et navn på riveren, i dette tilfælde mit_mssql_data, man kan have flere rivers de skal blot have forskellige navne.
Så har jeg defineret at vi vil brugere MSSQL driveren, her kunne det også have været end anden driver, alt efter hvad du har behov for og hvilke connectorer du har installeret.
I url’en defineres MSSQL serveren og databasen vi vil benytte.
SQL sætningen skal man huske at benytte ? for hver værdi, og sætte dem i parameter arrayet.
Husk at definere et index og type som data fra databasen skal importeres som.
Relaterede indlæg
Comments (0)